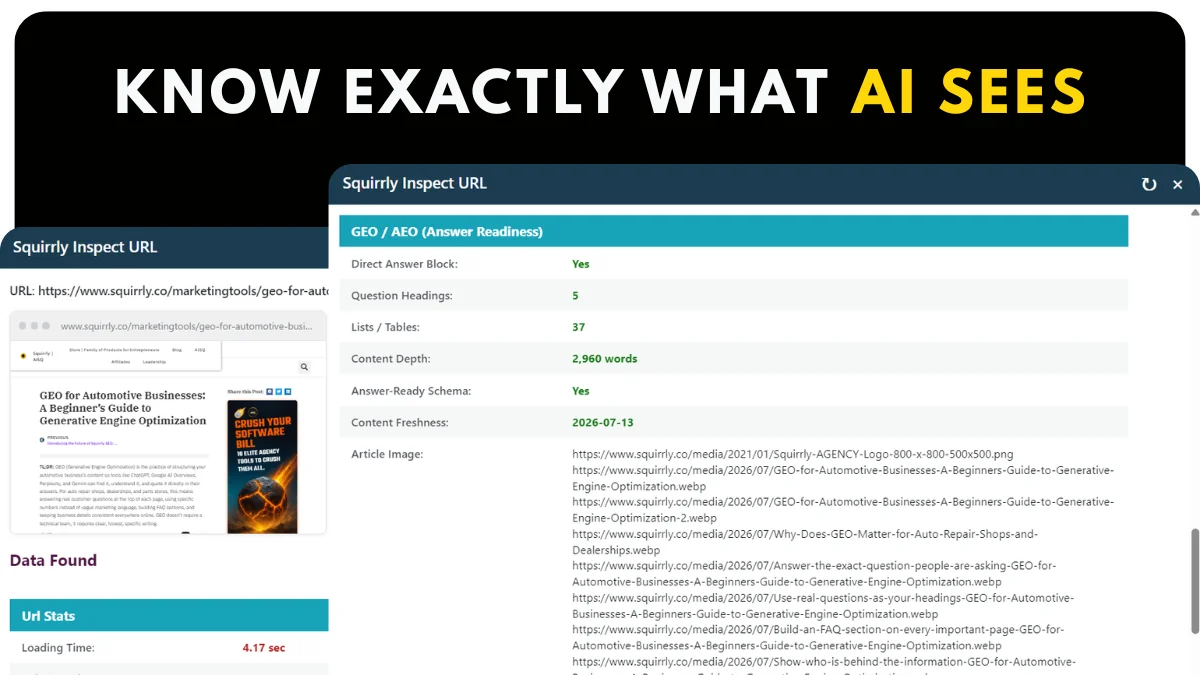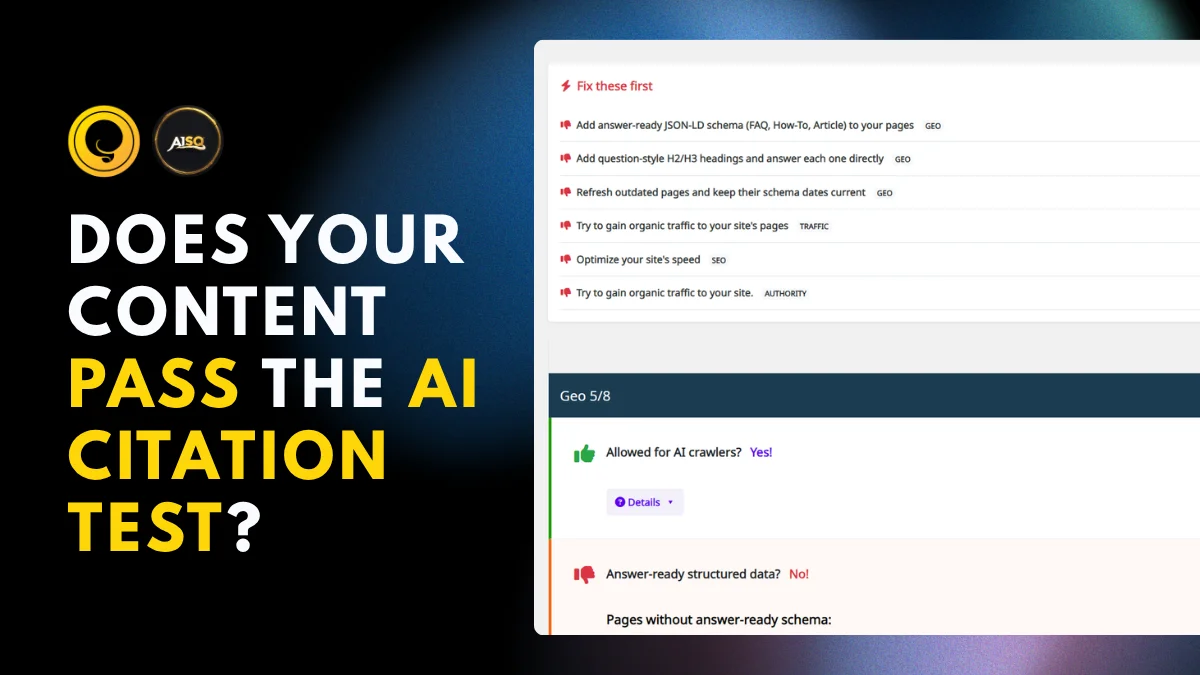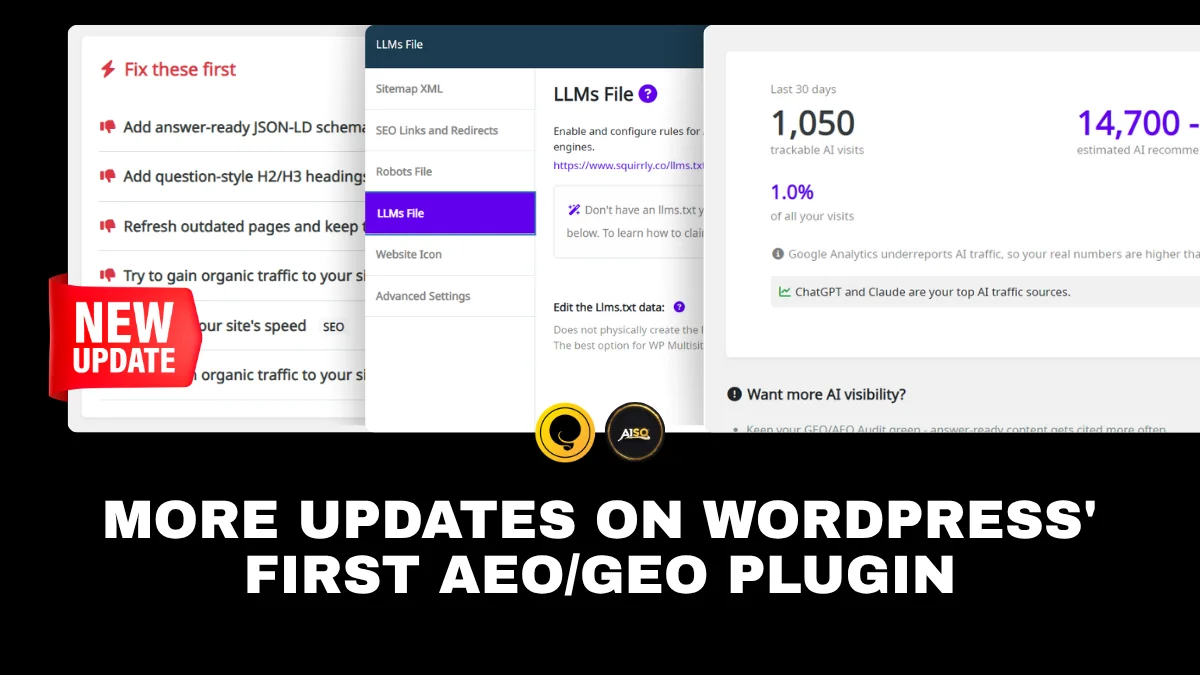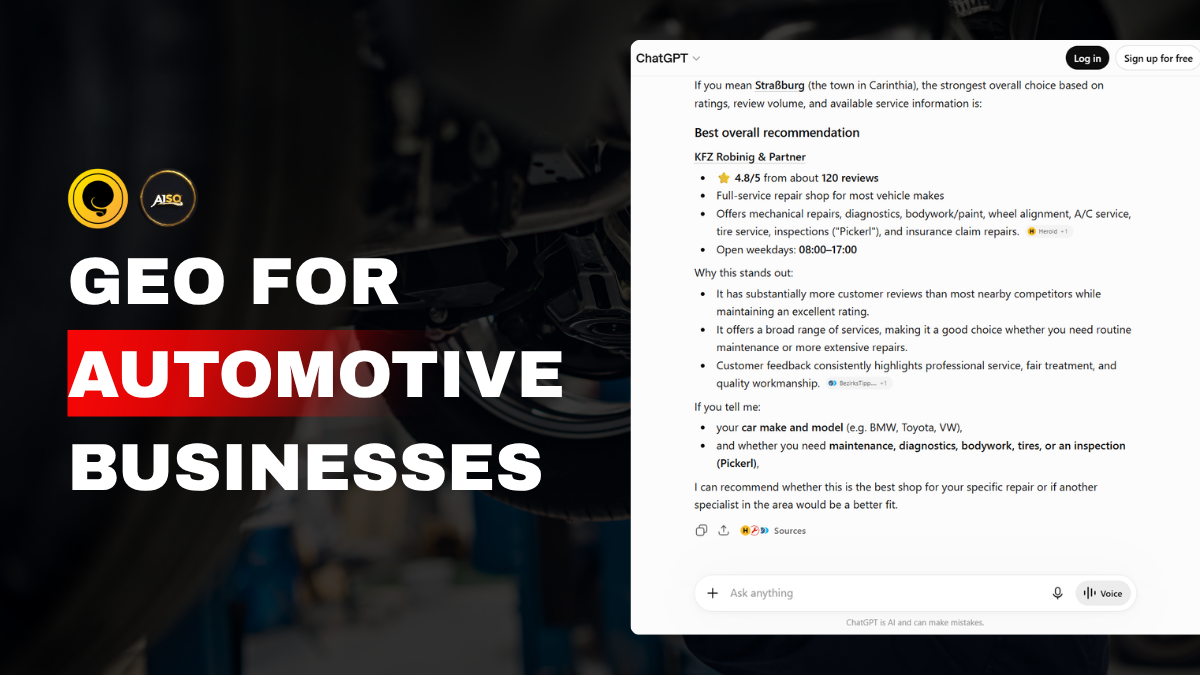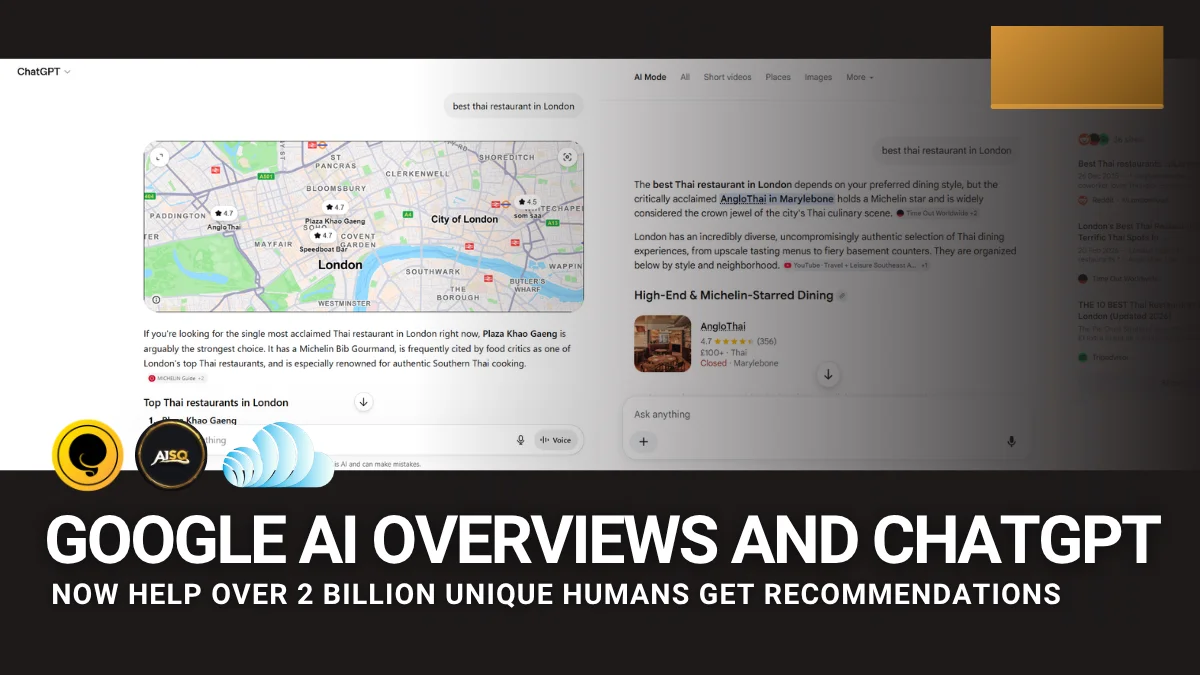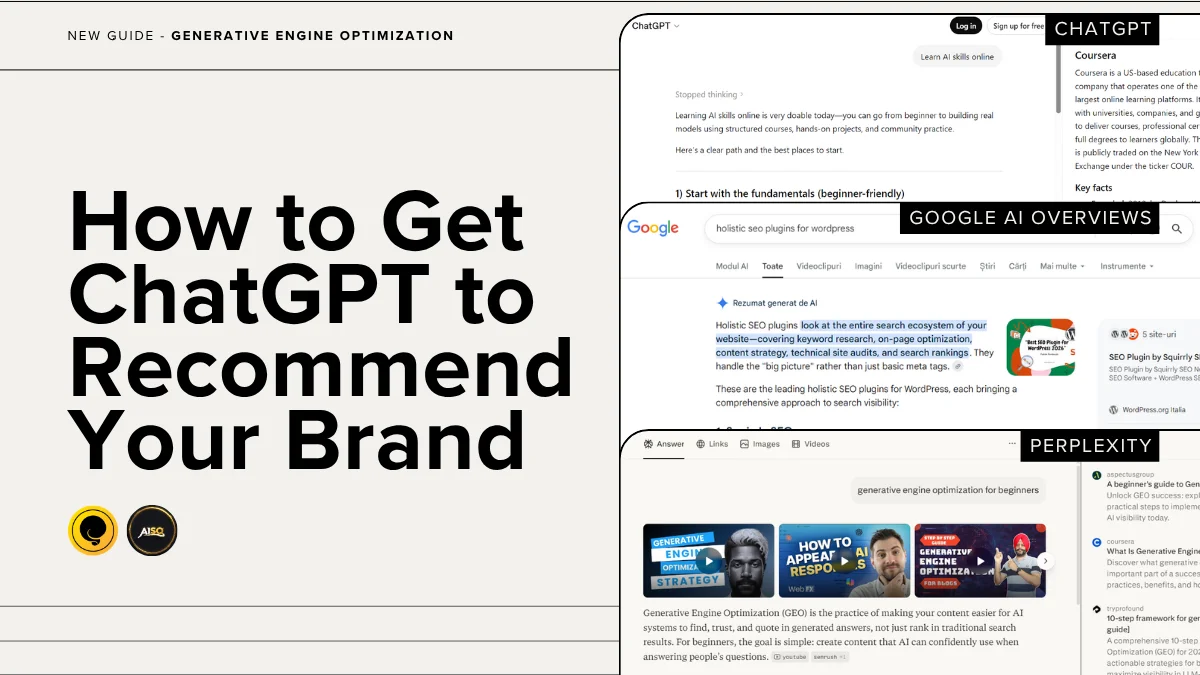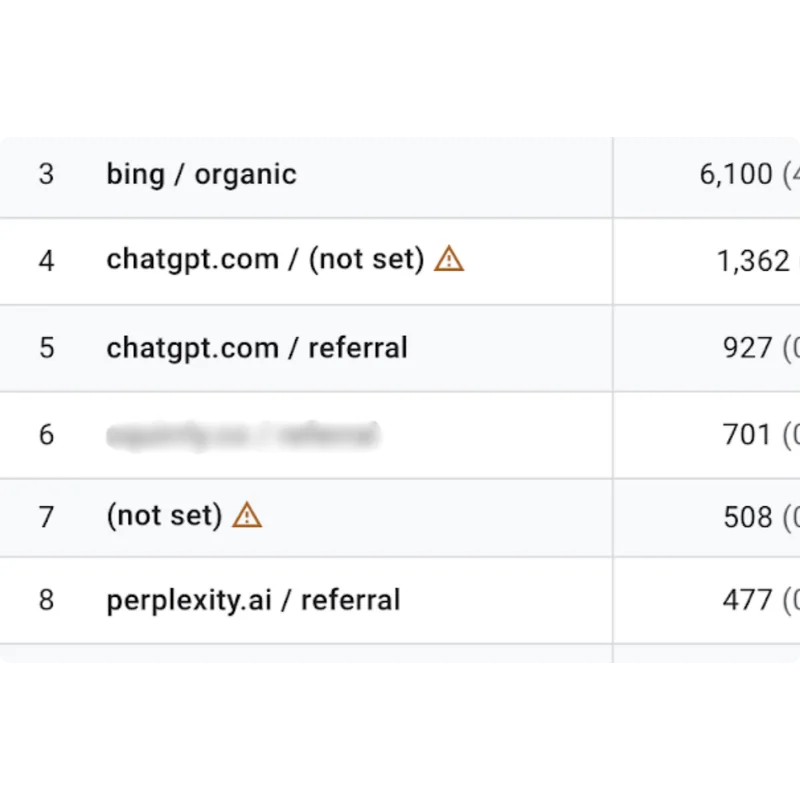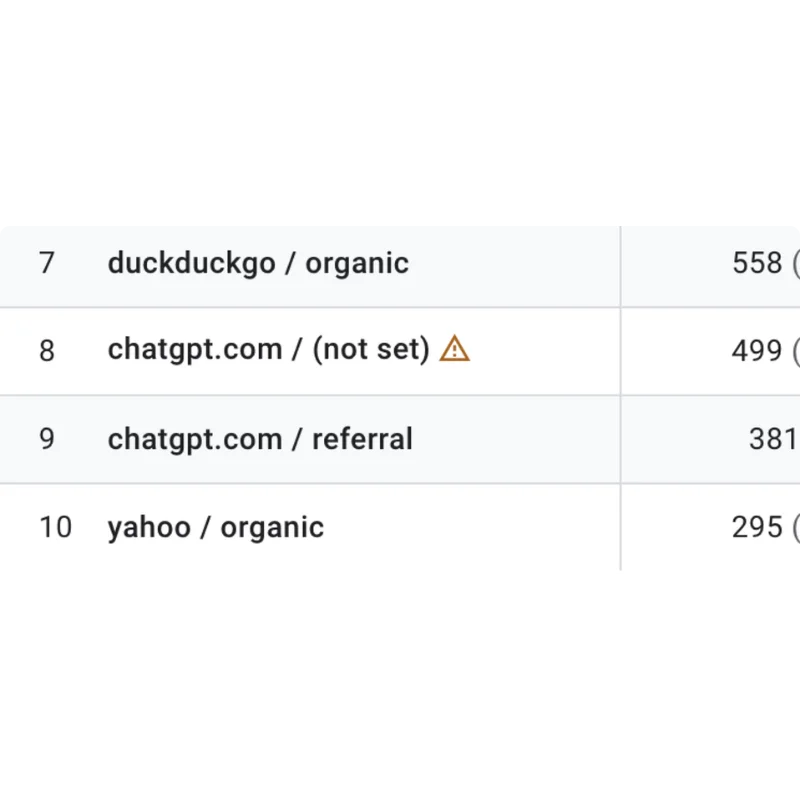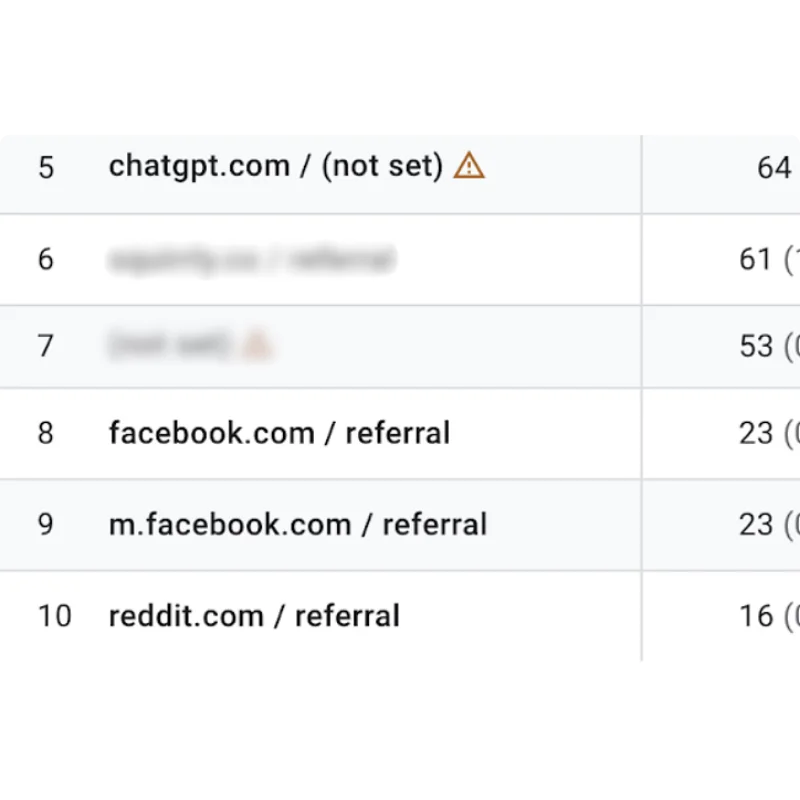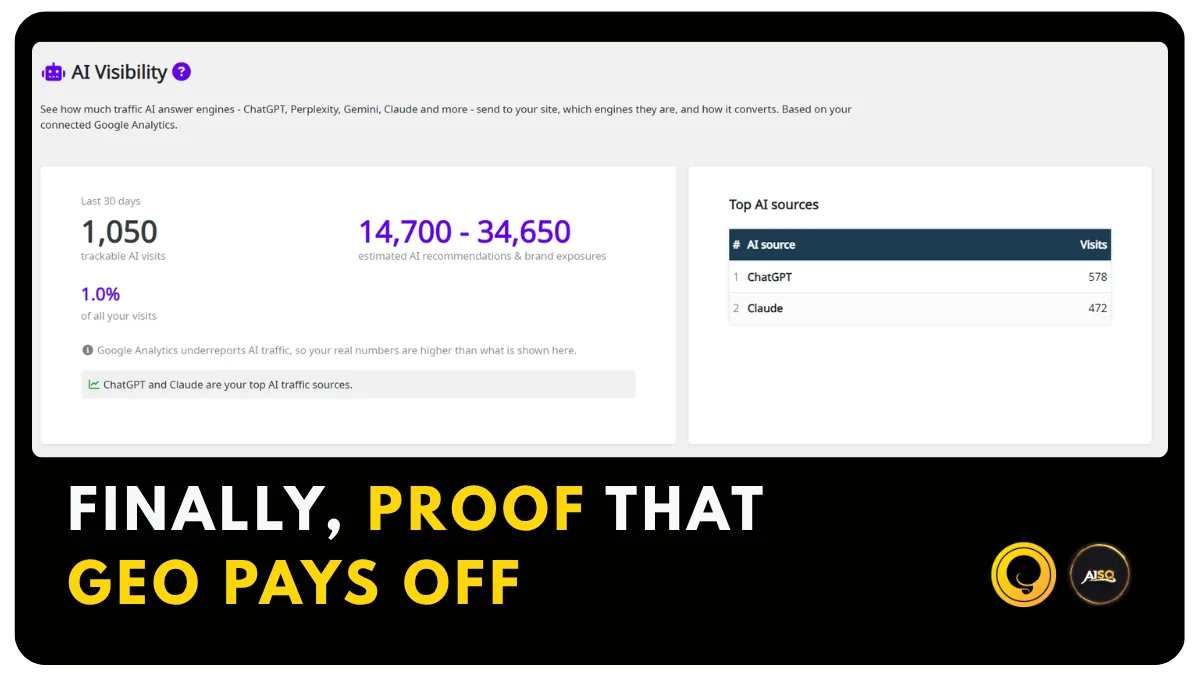
Introducing AI Visibility! What We Show Is 100% Provable
The new AEO/GEO Audit from Squirrly SEO shows you exactly what to fix so AI engines can find and cite your content. Which raises the obvious next question. You do the work. How do you know it’s actually paying off?